BLOG 1
MARCH 24, 2026
Why do you care about TRMs?
Cheaper, faster, and more accurate. Got your attention?
Here's the research paper link: https://arxiv.org/abs/2512.11847v1
Tiny recursive models are a small model (so millions not billions parameters), that refines its internal state (recursive) instead of token-by-token like LLMs.
Why should it matter to you? I see a plethora of possibilities and potential that this model and concept can bring to both your projects and even corporate workflow for my fellow recruiters (I hope you've made it this far).
But before we get into that, I do want to walk through the research, so I highly recommend you read just the abstract of the paper (first paragraph) and get a little more familiar with it to follow along with the next video.
Page 12 has the open sourced GitHub repository if you're impatient and want to see the code and tests for yourself.
BLOG 2
MARCH 25, 2026
What and why the research? + Abstract
We know what it does, we don't know how.
The model outputting an amazing Pass@1 (meaning the best one) result is enough to prove the potential exists and the dreams can live.
How was it tested? In a nutshell, we eliminated certain aspects of the puzzle (puzzle ID) and saw how the algorithm behaved.
Failed: the puzzle ID mattered, therefore important.
Succeeded: worked without puzzle ID, therefore doesn't matter. Test beyond: how much more did it struggle to succeed.
As we narrow down what matters to it, we narrow down to understanding the behavior of the algorithm.
Paper link: https://arxiv.org/abs/2512.11847v1
BLOG 3
MARCH 26, 2026
Model Walkthrough: Base vs Annotated
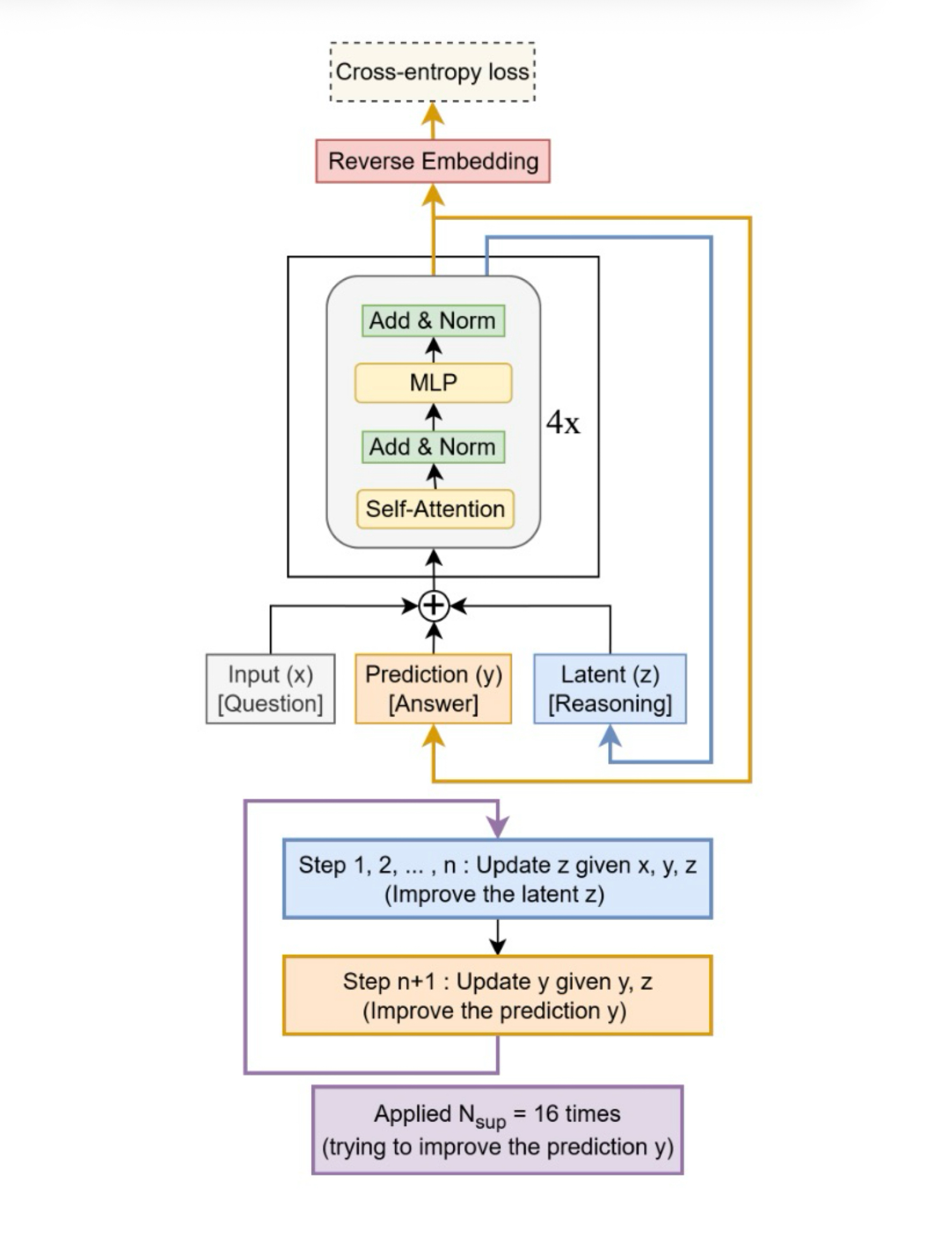
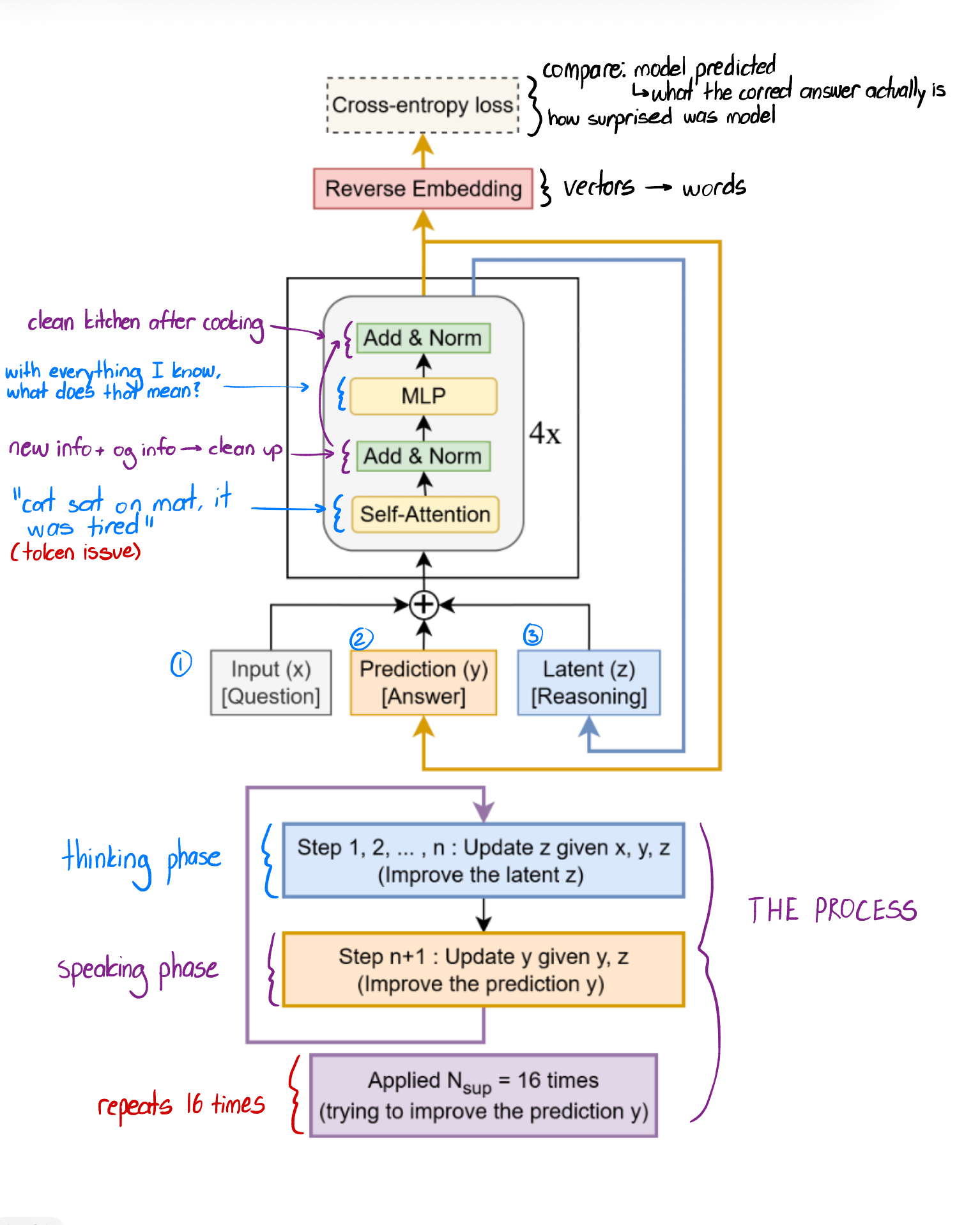
1. x (question) enters the model, y (answer) and z (reasoning) are output from the recursion.
2. The near copleted asnwer is obtained after the first recursion (look at visual below)
-> in recursion, context and infro building solved: outputs y and z
-> y and z ferment in the block and the final output it released
-> converted from vector to wording

BLOG 4
MARCH 28, 2026
TRM Implementation Scenario
Key term: Tokenization
-> LLM tokenization is the process of breaking text into smaller units called tokens, such as words, subwords, or characters, so a language model can convert them into numbers and process them.
THIS is what makes LLMs expensive. THIS is the issue I want to tackle.
The average engineer will use about $250k worth of tokens in a year, so let's go over a scenario of a QA system, and how we can visually picture this model being used to reduce tokenization.
All in all: TRM eliminated irrelevant garbage -> reduces unnecessary tokenization -> corporate save money -> everyone happy
BLOG 5
MARCH 29, 2026
Our 4 Big Why's (Introduction) (1)
Here are the 4 key factors we researched.
1. Role of test-time compute
2. Dependence on puzzle ID
3. Effective depth of recursion
4. Impact of augmentation on the solution distribution

We go over the questions raised from each of these factors acknowledging what we need to eventually know to understand the behavior of the model down to the pin.
BLOG 6
MARCH 30, 2026
What Did We Do? (Contributions) (1.1)
Following the 4 factors we needed to understand, here are the points we tackled:
1. Ensemble contribution
2. Puddle-ID Dependence
3. Recursion trajectory analysis
4. Training dynamics under augmentation

Using a "did - found - conclusion" model, I go over how we approached each why to find its how and what.
BLOG 7
APRIL 2, 2026
Related papers (step into the past) (2 – 2.3)
The TRM was an "update" from the HRM (hierarchical recursive model), which was a model with smaller models and more parameters within.
We go over:
1. Why the HRM wasn't the method
2. What the TRM fixes and why it's better
3. The difference in both thought-chains


BLOG 8
APRIL 5, 2026
Updated TRM implementation + first problem
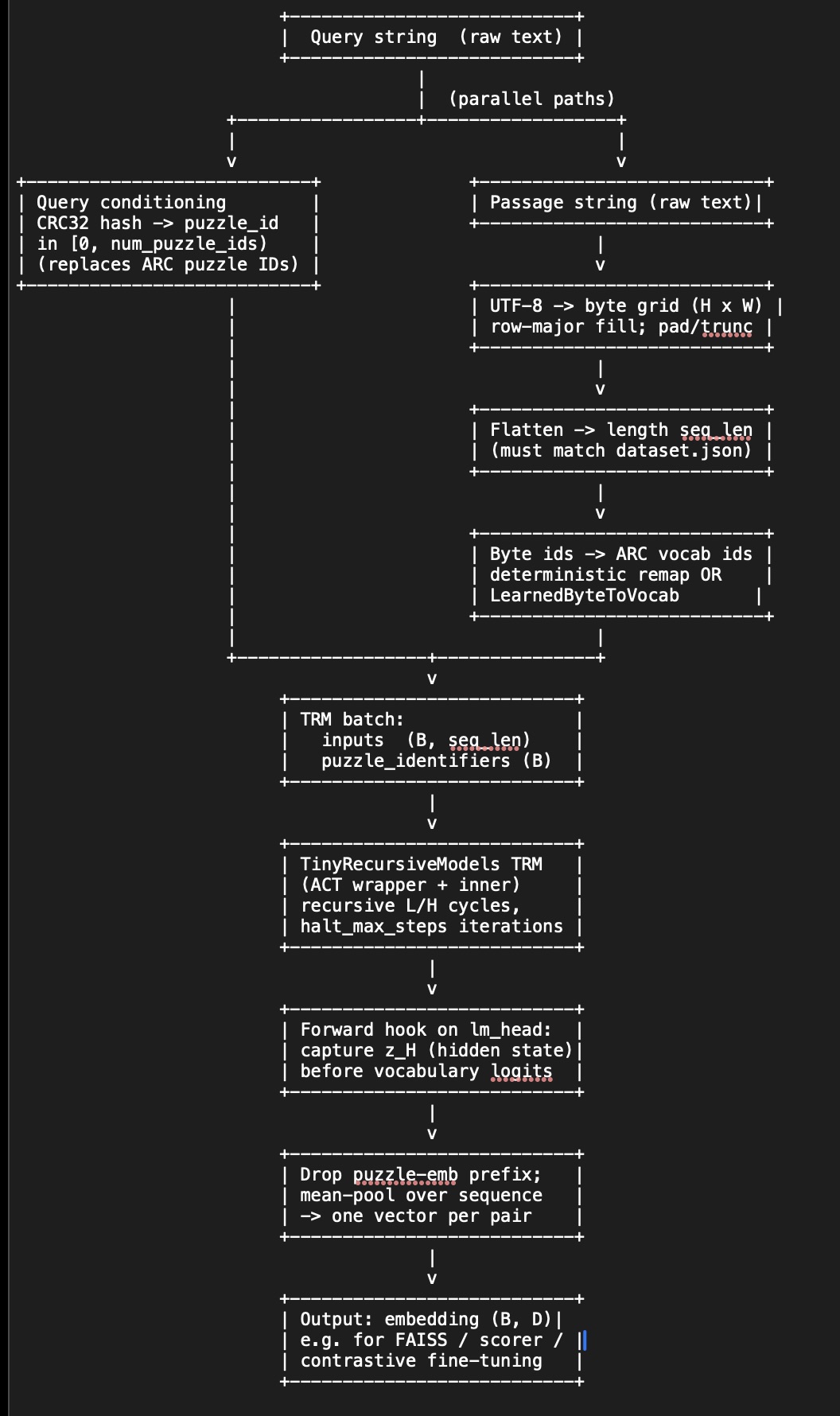
Long story short: TRM does NOT take raw text as input.
After going through a better detailed implementation flowchart, we see where the TRM is used and dig into our new roadblock.
Question: How can we update the TRM to comprehend text input and not just pixel to pixel play?

BLOG 9
APRIL 8, 2026
Project - Phase A
Our approach to "no text-value" TRM is to speak in its language. Turning our words into a byte grid will be our first trial at this (probably will not be our last).
Updated flowchart and notes: